[내멋대로 딥러닝]ep.2
합성곱 신경망(Convolution Neural Network)
대부분의 컴퓨터 비전 애플리케이션에 사용되는 합성곱 신경망을 구성해보자.
ep.1에서 다뤘던 완전 연결 신경층(Dense Layer)으로 만든 모델은 사실 비전 애플리케이션에는 그렇게 적합하지 않다.

비전처리를 효율적으로 하기 위해서는 이미지의 특징을 잡는 것이 중요하다. 위의 새 이미지를 예로 들면, 새의 부리에 대한 특징을 각 이미지에서 찾아내면 해당 이미지는 새가 있을 확률이 높아진다. 이 때 부리가 그림의 어느 좌표에 존재하는지는 크게 상관이 없다.
그런데 완전 연결 신경층에서 데이터를 학습하게 된다면 같은 부리여도 부리의 좌표가 다르면 새로운 패턴으로 인식하게 되어 학습 시에 비효율적으로 학습하게 된다.
하지만 합성곱 신경망(컨브넷)은 다르다.
이미지는 지역 패턴으로 분해될 수 있다. 컨브넷으로 학습된 이 패턴은 평행이동 불변성을 지녀서 이미지의 다른 곳에서도 이 패턴을 인식할 수 있다.
또한 컨브넷은 패턴의 공간적 계층구조를 학습할 수 있다. 첫 번째 합성곱 층이 작은 지역 패턴을 학습하면, 두 번째 합성곱 층은 첫 번째 층의 특성으로 구성된 더 큰 패턴을 학습하는 식이다. 이런 방식을 사용하여 컨브넷은 매우 복잡하고 추상적인 시각적 개념을 효과적으로 학습할 수 있다. 점점 학습하는 깊이가 깊어진다고 볼 수 있다.
합성곱의 연산
합성곱은 합성곱 연산을 통해 이미지의 특징을 추출하고 이를 학습시킨다.
n x m 행렬의 필터(커널)을 이미지를 훑어가며 겹쳐지는 n x m 범위와 내적하는 방법이다.
(같은 위치의 숫자혹은 벡터 끼리 곱하면 된다.)
(벡터는 깊이가 있는 값이라고 생각하면 되고 색상이 들어가는 이미지의 경우 RGB의 3깊이를 가진 값으로 생각하면 된다. 흑백은 회색의 정도 1깊이를 가진다.)
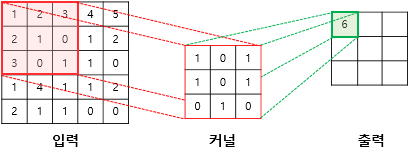
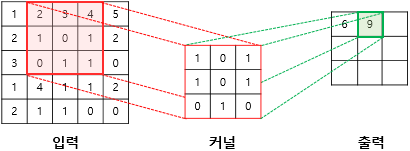
...이러한 합성곱 연산 과정을 반복해서 특성 맵을 얻는다.

다만 이렇게 가면 층을 거듭할 수록 특성맵의 크기가 점점 줄어든다. 이를 적절하게 관리하는 방법 중에 패딩(Padding)과 스트라이드(Stride) 라는 방법이 존재하는데 다른 포스팅에서 다뤄보겠다.
최대 풀링 연산
컨브넷만 사용하여 모델을 만들면 크게 두 가지 단점이 있다.
1. 합성 곱에서 사용하는 필터에 너무 적은 범위의 정보가 들어가게 된다.
2. 최종 특성맵의 원소가 많아져서 마지막에 계산하는 가중치 파라미터가 너무 많아 심각한 과대적합이 발생한다.
그래서 풀링 연산을 담당하는 층을 합성곱 층 사이사이에 집어넣어 이를 보정해주어 이 문제를 해결한다.
최대 풀링 연산은 a x b 크기의 윈도우(합성곱에서의 필터와 비슷한 의미이다)에서 최대값을 하드코딩으로 뽑아낸다. 이는 a x b 크기의 특성을 더 1칸의 특성 맵 안에 두어 출력되는 특성맵이 더 큰 범위의 정보를 나타내개 해준다.
모델 구현
1. 학습시킬 데이터들을 각 폴더에 위치시킨다.
import os, shutil
#원본 데이터셋을 압축 해제한 디렉터리 경로
original_dataset_dir = './datasets/cats_and_dogs/train'
#소규모 데이터셋을 저장할 디렉터리
base_dir = './datasets/cats_and_dogs_small'
#훈련, 검증, 테스트 분할을 위한 디렉터리
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
#훈련용 고양이 사진 디렉터리
train_cats_dir = os.path.join(train_dir, 'cats')
#훈련용 강아지 사진 디렉터리
train_dogs_dir = os.path.join(train_dir, 'dogs')
#검증용 고양이 사진 디렉터리
validation_cats_dir = os.path.join(validation_dir, 'cats')
#검증용 강아지 사진 디렉터리
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
#테스트용 고양이 사진디렉터리
test_cats_dir = os.path.join(test_dir, 'cats')
#테스트용 강아지 사진 디렉터리
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(base_dir)
os.mkdir(train_dir)
os.mkdir(validation_dir)
os.mkdir(test_dir)
os.mkdir(train_cats_dir)
os.mkdir(train_dogs_dir)
os.mkdir(validation_cats_dir)
os.mkdir(validation_dogs_dir)
os.mkdir(test_cats_dir)
os.mkdir(test_dogs_dir)
#처음 1,000개의 고양이 이미지를 train_cats_dir에 복사합니다.
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
#다음 500개의 고양이 이미지를 validation_cats_dir에 복사합니다.
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
#다음 500개의 고양이 이미지를 test_cats_dir에 복사합니다.
fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
#처음 1,000개의 강아지 이미지를 train_dogs_dir에 복사합니다.
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
#다음 500개의 강아지 이미지를 validation_dogs_dir에 복사합니다.
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
#다음 500개의 강아지 이미지를 test_dogs_dir에 복사합니다.
fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
2. 합성곱 신경망을 학습시킬 모델을 구현한다.
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3,3), activation='relu',
input_shape=(150,150,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))* Flatten : 입력데이터를 1차원으로 평탄화해 이후의 레이어에서 처리하기 쉽게 만들어준다.
* 마지막 층에 Dense 층을 사용해 분류를 위한 층을 더한다.
3. 모델의 손실함수, 옵티마이저, 평가지표 등을 추가해 컴파일한다.
from keras import optimizers
import tensorflow as tf
#optimizer=optimizers.RMSprop(learning_rate=1e-4),
model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.legacy.RMSprop(learning_rate=1e-4),
metrics=['acc'])* 이진 분류 작업이기 때문에 binary_crossentropy 함수를 사용했다.
4. 케라스 내장함수인 ImageDataGenerator을 사용해 이미지를 전처리한다.
from keras.preprocessing.image import ImageDataGenerator
#모든 이미지를 1/255로 스케일을 조정합니다.
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir, #타깃 디렉터리
target_size=(150, 150), #모든 이미지를 150 150 크기로 바꿉니다.
batch_size=20,
class_mode='binary' #binary_crossentropy 손실을 사용하기 때문에 이진 레이블이 필요ㅂ니다.
)
validation_generator = test_datagen.flow_from_directory(
validation_dir, #타깃 디렉터리
target_size=(150, 150),
batch_size=20,
class_mode='binary'
)* 사진파일을 읽는다 -> JPEG 콘텐츠를 RGB 픽셀 값으로 디코딩한다. -> 부동소수 타입 텐서로 변환한다. -> 픽셀 값 사이를 0~1 사이로 조정한다.(신경망은 작은 입력값을 선호함)
* flow_from_directory 는 파일이 있는 디렉토리의 순서대로 레이블 값을 작성해준다.
5. 모델을 학습시킨다.
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50
)현재 이 모델은 정확도가 약 70퍼센트 정도 나오는데
다음 장의 작업들을 통해 정확도를 끌어올리는 포스팅을 진행하겠다
야호~