2023. 7. 31. 16:33ㆍAI/딥러닝
(틀릴 수 있음 주의)
예전에 간단하게 딥러닝 개념만 훑은 적이 있는데
개인적으로 개발을 시작해보려 한다.
앞으로 나올 얘기들은 주관적인 이해에 따른 글 이므로 그릇된 정보일 가능성이 크다!
알아서 필요한 것만 필터링해야 한다.
1. 딥러닝
딥러닝은 머신러닝의 한 방법으로, 인공 신경망을 구현하고 이 모델을 학습시켜 판단 기준을 세운 후에 들어오는 정보에 대한 판단을 가능하게 하는 것이다.

인공신경망은 신경세포(뉴런)처럼 여러 부분이 얽혀서 이루어져 있다고 해서 이름이 붙은 것이다. 하지만 실제 작동 방법은 조금 다르다고 한다.
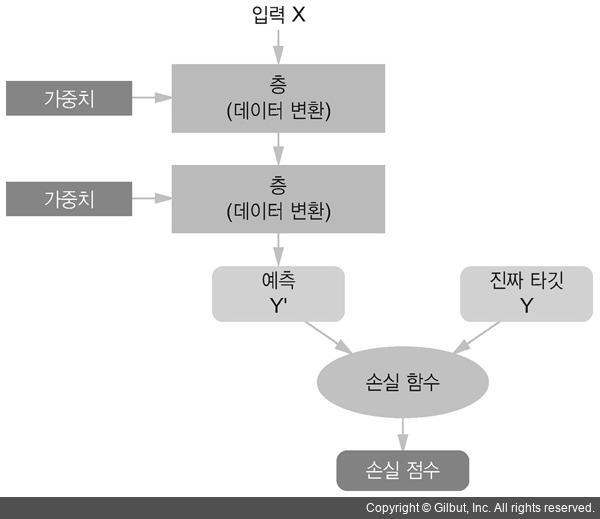
1. 데이터가 입력되면 각 층(Hidden Layer)에서 가중치(벡터)를 사용해 데이터를 변환하는 과정을 거쳐 입력 데이터에 대한 예측값을 도출한다.
2. 예측값과 정답을 손실함수를 이용하여 손실점수를 도출한다.
3. 손실점수를 최소화 하는 방향으로 Optimizer가 가중치를 조정한다.
이러한 과정을 반복해서 손실값을 최소화하는 가중치가 적용된 모델을 만들어내는 것이 기본적인 딥러닝이다.(아마도)
2. (내가 이해한)가중치
모든 디지털 정보는 벡터로 표현이 가능하다.
이미지 데이터는 픽셀의 위치와 픽셀의 색상정보인 2차원 벡터로 표현이 가능하고 동영상 데이터는 이미지 정보에 시간 축이 더해져 3차원 데이터로 표현이 가능하다. 모든 데이터가 벡터로 표현이 가능하다면 해당 벡터와 행렬을 곱하면 크기와 표현을 변경할 수 있고, 이러한 과정을 반복하면 판단을 내리는 지표인 단일 값으로 변환이 가능하다. 이 단일 값으로 변환한 값을 예측값이라 하고 이를 정답과 비교할 수 있는 것이다.

해서 손실함수의 최솟값의 부분을 찾아 행렬값들을 변화시키는 과정이 최적화(Optimizing)이고 그것을 시켜주는 알고리즘이 옵티마이저(Optimizer)이다
W가 가중치이고 y_pred가 예측값이고, x가 입력값, y가 정답이라고 했을 때, 손실값을 나타내는 식은 다음과 같이 나타낼 수 있다.
y_pred = dot(W, x)
loss_value = loss(y_pred, y)위에서 x와 y가 고정되어있다면 결국 W를 변수로하는 함수를 나타내는 식으로 표현할 수 있다.
loss_value = f(W)즉 가중치 행렬이 변수인 함수의 최솟값을 찾아가는 것이고 간단하게 나타내면 행렬의 미분을 통해 기울기를 찾아 최솟값을 찾는 것이다
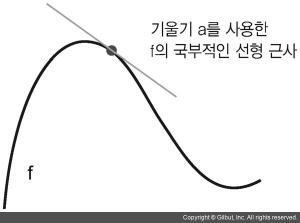
예제
(책 그대로 구현)
우선 WSL(리눅스용 윈도우 하위시스템)으로 ubuntu20.04를 설치해 사용했다.
sudo apt update
sudo apt install python3-dev python3-pip
sudo pip3 intall -U virtualenv파이썬용 라이브러리들을 다운/업데이트 해준다.
virtualenv는 파이썬 가상환경을 제공해주어 프로그램별로 충돌하지 않게 해준다. mac용으로 작업할 땐 conda를 사용했다.
pip3 install --user --upgrade tensorflow-cpu텐서플로우를 설치한다. 그냥 tensorflow로 설치하면 gpu용이 설치된다.
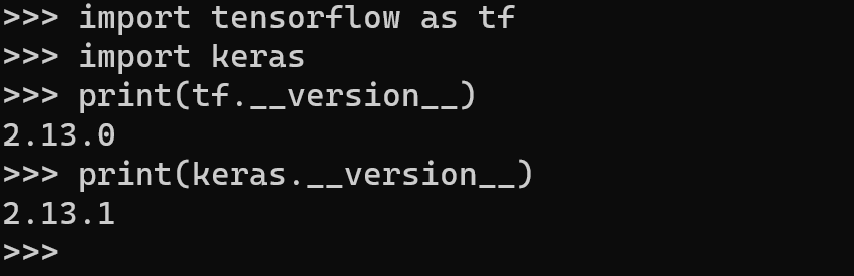
텐서플로우와 케라스가 정상적으로 설치되어 임포트 된다.
jupyter notebook을 설치하고 실행시킨 후 코드를 작성한다.
import tensorflow as tf
import keras
import numpy as np딥러닝 라이브러리들을 임포트한다.
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(
num_words=10000)케라스에는 기본적으로 연습용 데이터인 imdb가 존재한다. 영화 리뷰의 긍정 부정 평가 데이터이다.\
train_data에는 특정 단어 사전인덱스와 리뷰가 매핑되어있다. 아래 코드를 실행하면 어떤 리뷰로 작성되어 있는지 확인할 수 있다.
word_index = imdb.get_word_index() # word_index는 단어와 정수 인덱스를 매핑한 딕셔너리입니다.
reverse_word_index = dict(
# 정수 인덱스와 단어를 매핑하도록 뒤집습니다.
[(value, key) for (key, value) in word_index.items()])
decoded_review = ' '.join(
# 리뷰를 디코딩합니다. 0, 1, 2는 ‘패딩’, ‘문서 시작’, ‘사전에 없음’을 위한 인덱스이므로 3을 뺍니다.
[reverse_word_index.get(i - 3, '?') for i in train_data[0]])
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
# 크기가 (len(sequences), dimension)이고 모든 원소가 0인 행렬을 만듭니다.
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # results[i]에서 특정 인덱스의 위치를 1로 만듭니다.
return results
x_train = vectorize_sequences(train_data) # 훈련 데이터를 벡터로 변환합니다.
x_test = vectorize_sequences(test_data) # 테스트 데이터를 벡터로 변환합니다.
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')vectorize_sequences 함수는 리뷰에 사용된 단어의 인덱스를 찾아 해당 위치를 1로 변경시켜 해당 단어가 사용되었음을 나타내는 벡터로 변환시켜준다.
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))모델에 층을 더해준다. Dense의 첫번째 인수는 해당 층의 은닉 유닛 수를 의미하며 이는 출력 벡터의 차원이 16차원임을 의미한다. activation은 활성화함수로서 판단의 기준을 제공해 가중치와 편향을 갱신하는데 사용되는 비선형 함수이다.
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])모델에 옵티마이저, 손실함수, 척도를 설정해준다.
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]학습 데이터를 훈련용과 검증용으로 나누어준다
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))배치 사이즈를 512로 하고 epoch를 20으로 해준다 -> 512개의 데이터를 통과시킬 때마다 가중치를 업데이트한다. 모든 데이터를 20바퀴 돌린다.
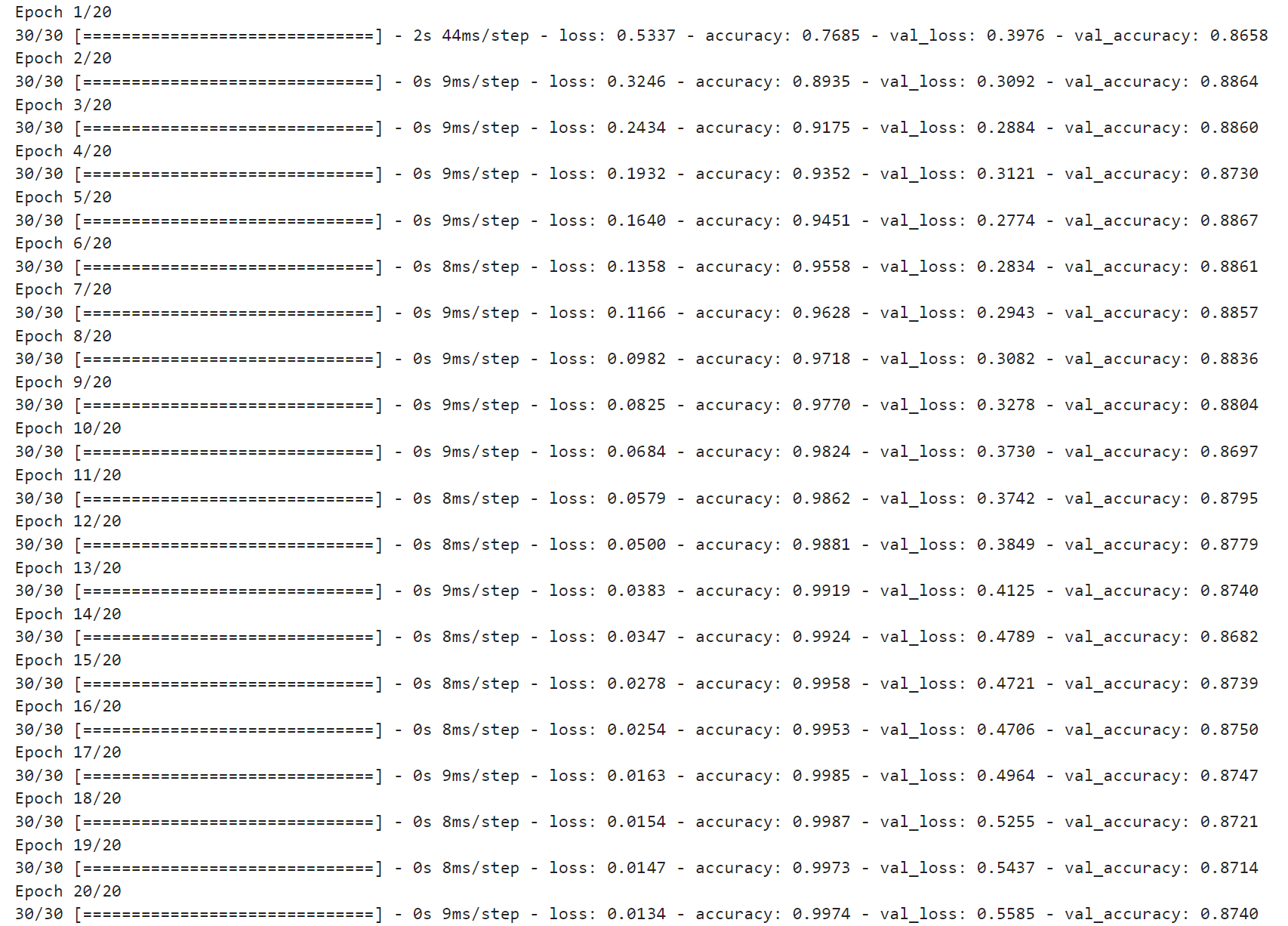
학습 완료~
'AI > 딥러닝' 카테고리의 다른 글
| [내멋대로 딥러닝] ep.3 합성곱 신경망 시각화 (0) | 2025.02.14 |
|---|---|
| [내멋대로 딥러닝]ep.2 (2) | 2023.08.29 |